当前,随着AI潮的风起云涌,尤其是今年,也被称之为“人工智能元年”,伴随着各类企业的“智慧”项目,使得机器学习,尤其是深度学习(Deep Learning,简称DL)在算法领域可谓是大红大紫。要学习深度学习,那么首先要熟悉神经网络(Neural Networks,简称NN)的一些基本概念。当然,这里所说的神经网络不是生物学的神经网络,我们将其称之为人工神经网络(Artificial Neural Networks,简称ANN)貌似更为合理。神经网络最早是人工智能领域的一种算法或者说是模型,目前神经网络已经发展成为一类多学科交叉的学科领域,它也随着深度学习取得的进展重新受到重视和推崇。
机器学习算法常用性能指标
机器学习算法常用性能指标总结
考虑一个二分问题,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也被 预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。
- TP:正确肯定的数目;
- FN:漏报,没有正确找到的匹配的数目;
- FP:误报,给出的匹配是不正确的;
- TN:正确拒绝的非匹配对数;
列联表如下表所示,1代表正类,0代表负类:
| | 预测1 | 预测0 |
|-|-|-|
| 实际1| True Positive(TP)| False Negative(FN)|
| 实际0|False Positive(FP)|True Negative(TN)|
pandas.read_csv参数详解
引子:pandas 的 read_csv 是数据集(文本)读取的一个常用函数,介于参数太多,且每次查阅官方 document 耗时,今天就索性将其整理,于人于己方便。
pandas.read_csv参数整理
pandas.read_csv 读取CSV(逗号分割)文件到DataFrame
也支持文件的部分导入和选择迭代
更多帮助参见:http://pandas.pydata.org/pandas-docs/stable/io.html
NVIDIA GPU 运算能力列表
CUDA GPUs
FROM: https://developer.nvidia.com/cuda-gpus
NVIDIA GPUs power millions of desktops, notebooks, workstations and supercomputers around the world, accelerating computationally-intensive tasks for consumers, professionals, scientists, and researchers.
Tensorboard 实例
Tensorboard 实例
构建数据流图
|
|
运行数据流图
|
|
TensorBoard Graph 效果:
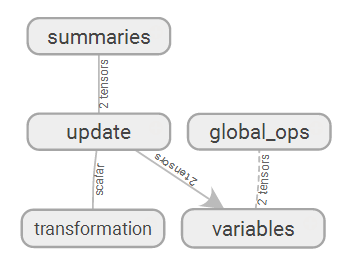
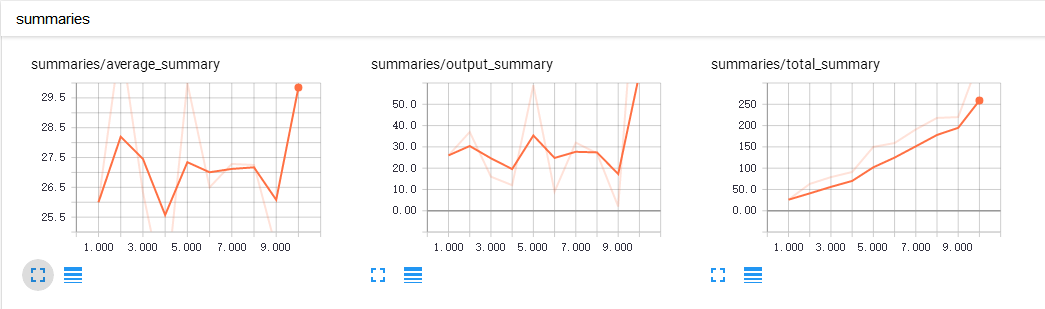
scalar 将显示汇总 summaries:
TensorFlow学习——TensorFlow Core
Tensorflow core
tf.train API
- optimizers —— 优化器
TensorFlow 提供了优化器来缓慢地更改每个变量,从而最大程度的降低损耗函数。
eg. gradient descent:
|
|
训练线性回归模型完整的代码:
|
|
tf.estimator
tf.estimator 作为 TensorFlow 高级库,简化了机器学习的机制,其中包括:
- 运行训练循环
- 运行评估循环
- 管理数据集
tf.estimator 定义了徐福哦常见的模型

